Storage and retrieval system for complex analytics on big sequence collections
Storage and retrieval system for complex analytics on big sequence collections
Data Series
Data series (a.k.a. sequences, or time series) are present in virtually every scientific and social domain: from health care, astronomy and biology, to finance and the internet-of-things.
Scaling to Big Data
In astronomy, there are applications with more than 70TB of spectroscopic sequence data, while by 2025 scientists are expected to collect around 2-40 ExaBytes of DNA sequence data.
Interactive Science
Our research aims to change a landscape, where database systems are used merely for storing and retrieving data, by enabling scientists to transparently use specialized query processing systems for accessing their sequential data.
Features
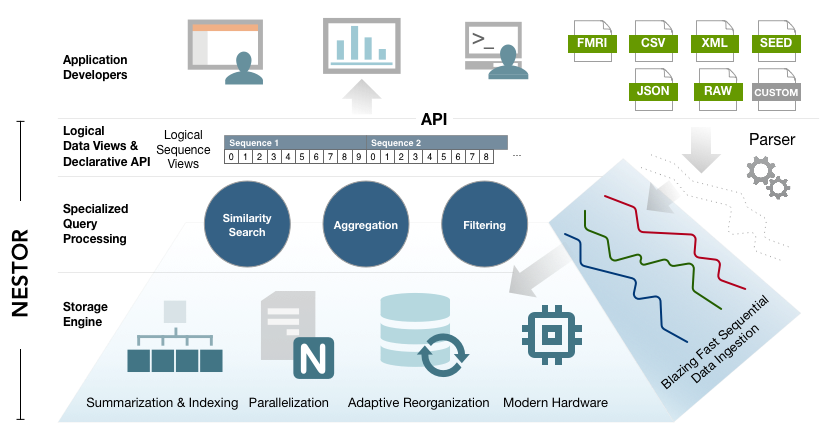
 NESTOR uses specialized summarization techniques for both reducing the size of data series, but also for allowing blazing fast analytics.
It additionally allows for the construction of domain specific indexes and decide when to use them by performing access path selection.
Such indexes facilitate both analytical (such as similarity search) as well as aggregation queries.
NESTOR uses specialized summarization techniques for both reducing the size of data series, but also for allowing blazing fast analytics.
It additionally allows for the construction of domain specific indexes and decide when to use them by performing access path selection.
Such indexes facilitate both analytical (such as similarity search) as well as aggregation queries.
 Both data storage, indexing, as well as query processing can scale to large clusters of computing nodes, allowing both for multi-TB data
processing but also for large analytical jobs to be performed in seconds.
Both data storage, indexing, as well as query processing can scale to large clusters of computing nodes, allowing both for multi-TB data
processing but also for large analytical jobs to be performed in seconds.
 NESTOR's storage layer continuously and adaptively reorganizes the underlying data layout in order to match the current workload,
without incurring any additional overhead.
NESTOR's storage layer continuously and adaptively reorganizes the underlying data layout in order to match the current workload,
without incurring any additional overhead.
 We utilize all modern hardware optimization techniques such as SIMD, NUMA-aware multi-processing, GPUs and SSD optimizations.
We utilize all modern hardware optimization techniques such as SIMD, NUMA-aware multi-processing, GPUs and SSD optimizations.

